- SEO
- GEO
- AI Traffic
- Web Analytics
- AI Visibility
AI Visibility Is the Missing Metric in Modern Web Analytics, Data Shows
Peasy reveals how AI platforms reshape SEO and AI visibility as Meta's ExternalAgent emerges among the most active AI crawlers.
The way AI companies gather content is changing faster than most website owners realize. While traditional SEO has focused on optimizing for Google Search, a new wave of AI crawlers - from OpenAI, Meta, Anthropic, Perplexity and others, is rapidly becoming a major force in how content is consumed, reused and surfaced inside large language models (LLMs).
At Peasy, we built an analytics platform to track AI traffic alongside traditional web activity. That means we can see not just human visits, but also server-side crawler activity and AI referrals that existing tools like Google Analytics 4 never capture.
Our latest crawl data suggests that Meta’s ExternalAgent crawler is emerging as one of the most active players, rivaling OpenAI bots in scale and often surpassing smaller competitors like Claude or Perplexity. This aligns with Meta’s public disclosures that its crawler is used for training AI models and improving products by indexing content directly.
With Meta simultaneously in negotiations with major publishers over content licensing and aggressively hiring AI talent for new research labs, it’s worth asking: is Meta in a rush to gather as much web content as possible before licensing agreements reshape the economics of training data?
What Our Data Reveals About AI Crawlers
Peasy’s crawler tracking identifies which AI agents visit sites, how frequently and for what purpose (indexing, search, chat retrieval). Here’s what stood out in recent weeks:
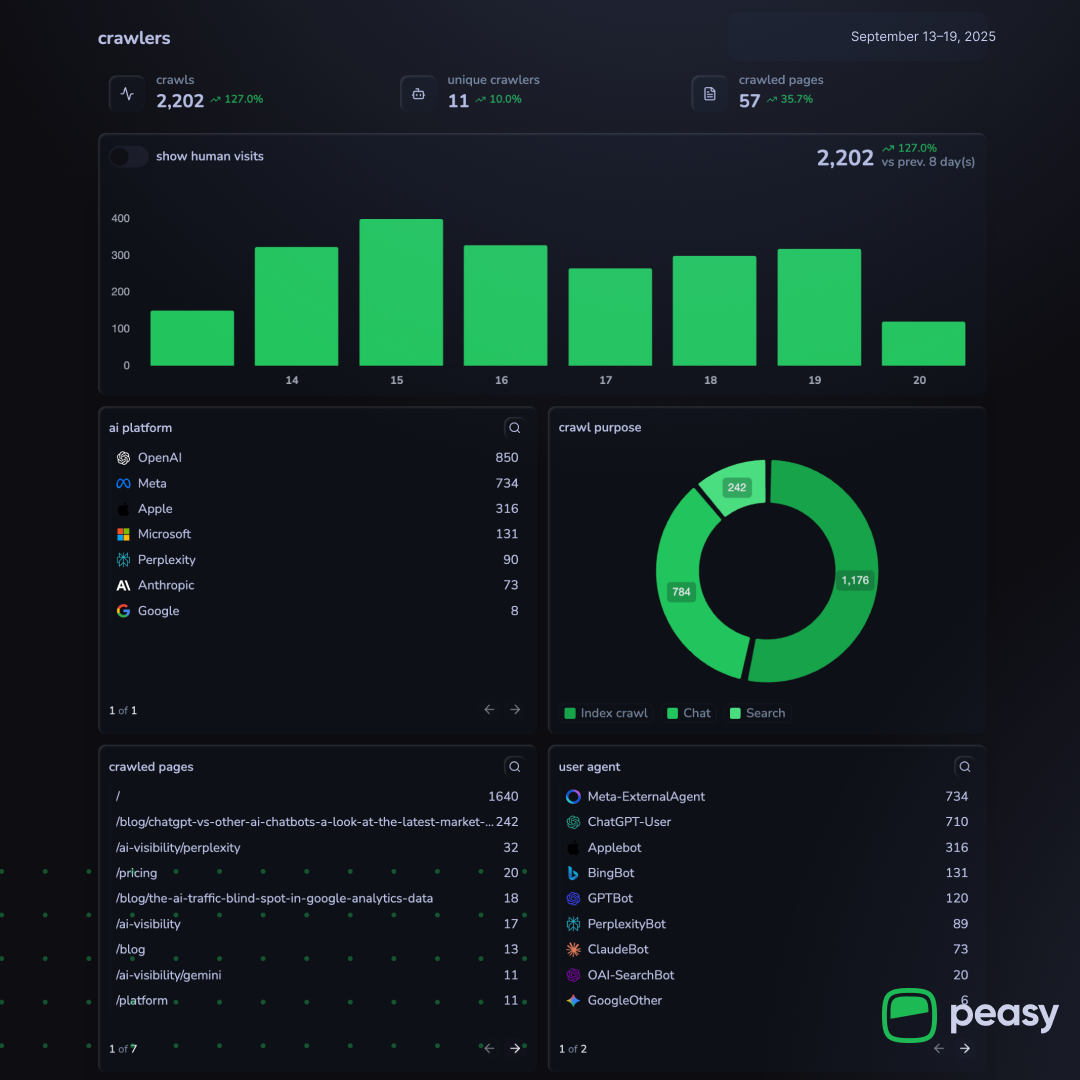 From September 13 to 20, Peasy tracked 2,202 crawls across 11 unique bots, led by OpenAI and Meta. |
|---|
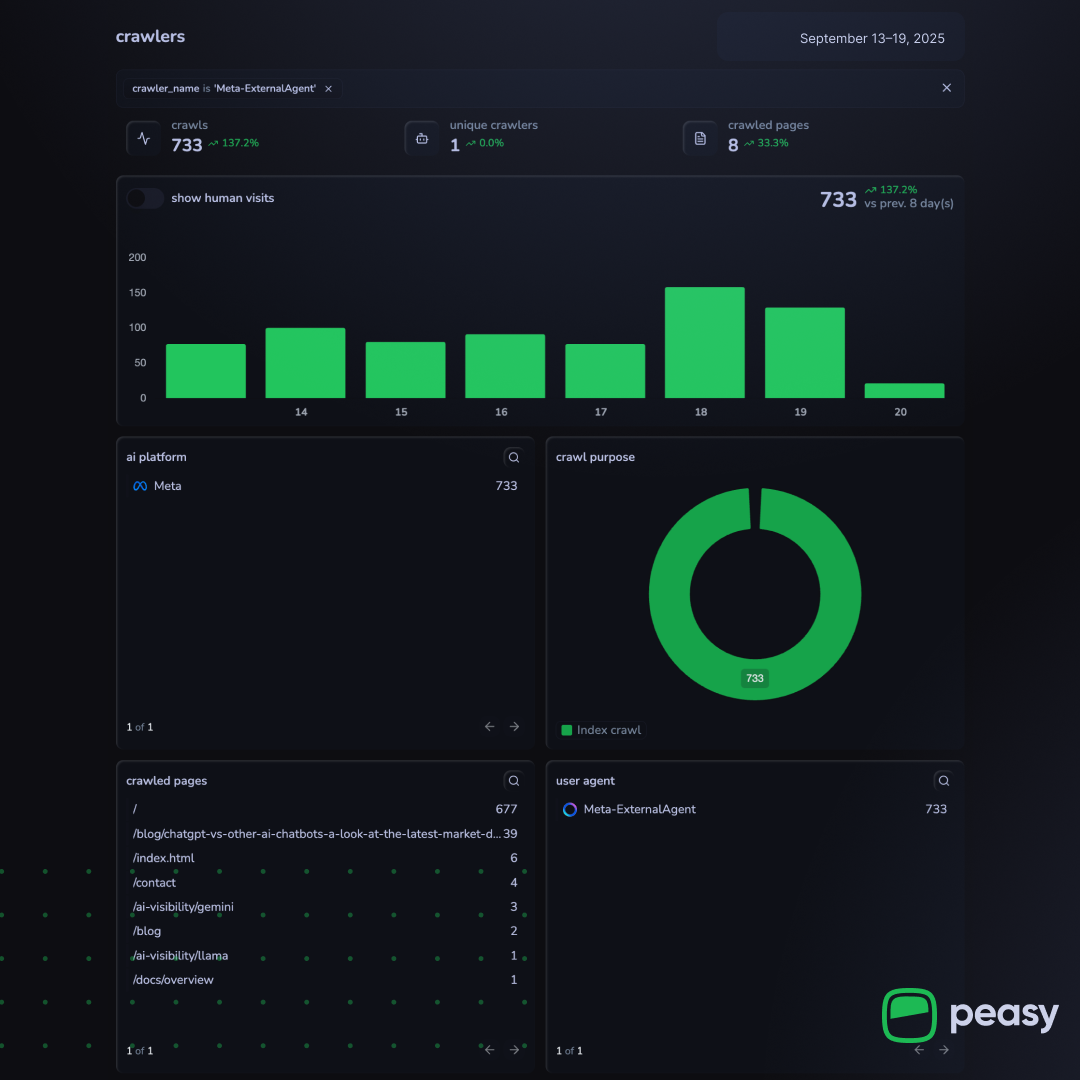 Meta’s ExternalAgent made 733 index crawls, with most activity targeting the homepage. | 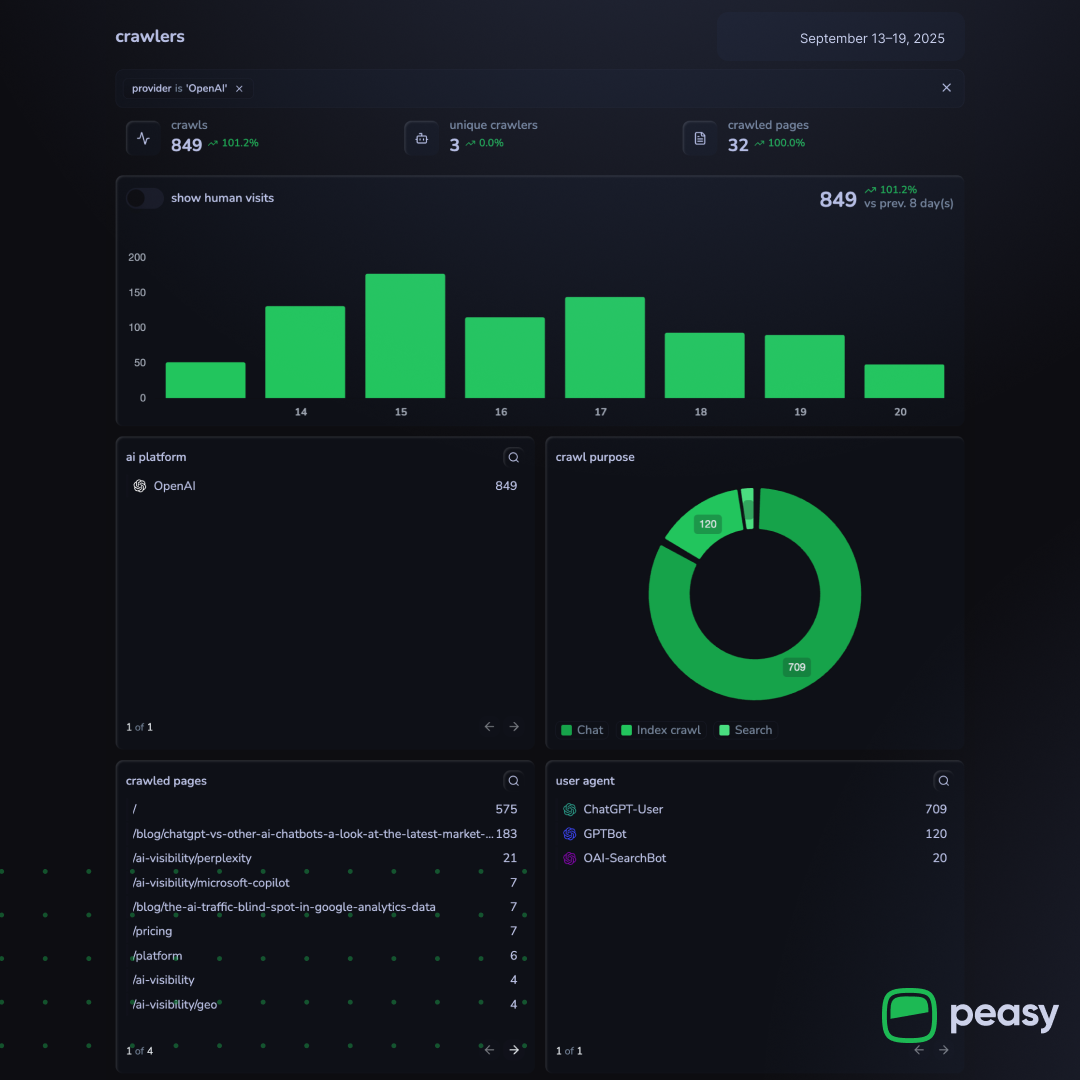 Peasy detected 849 OpenAI crawls, driven by ChatGPT-User, OAI-SearchBot and GPTBot agents. |
|---|
-
OpenAI bots remain dominant, with
GPTBotandChatGPT-Useraccounting for the highest overall crawl volume. -
Meta’s
ExternalAgentis second in scale, responsible for thousands of crawl requests on monitored sites. In several cases, Meta’s activity exceeded that ofClaudeBotorPerplexityBotcombined.
 Peasy recorded 73 ClaudeBot crawls from Anthropic, all logged as chat requests. | 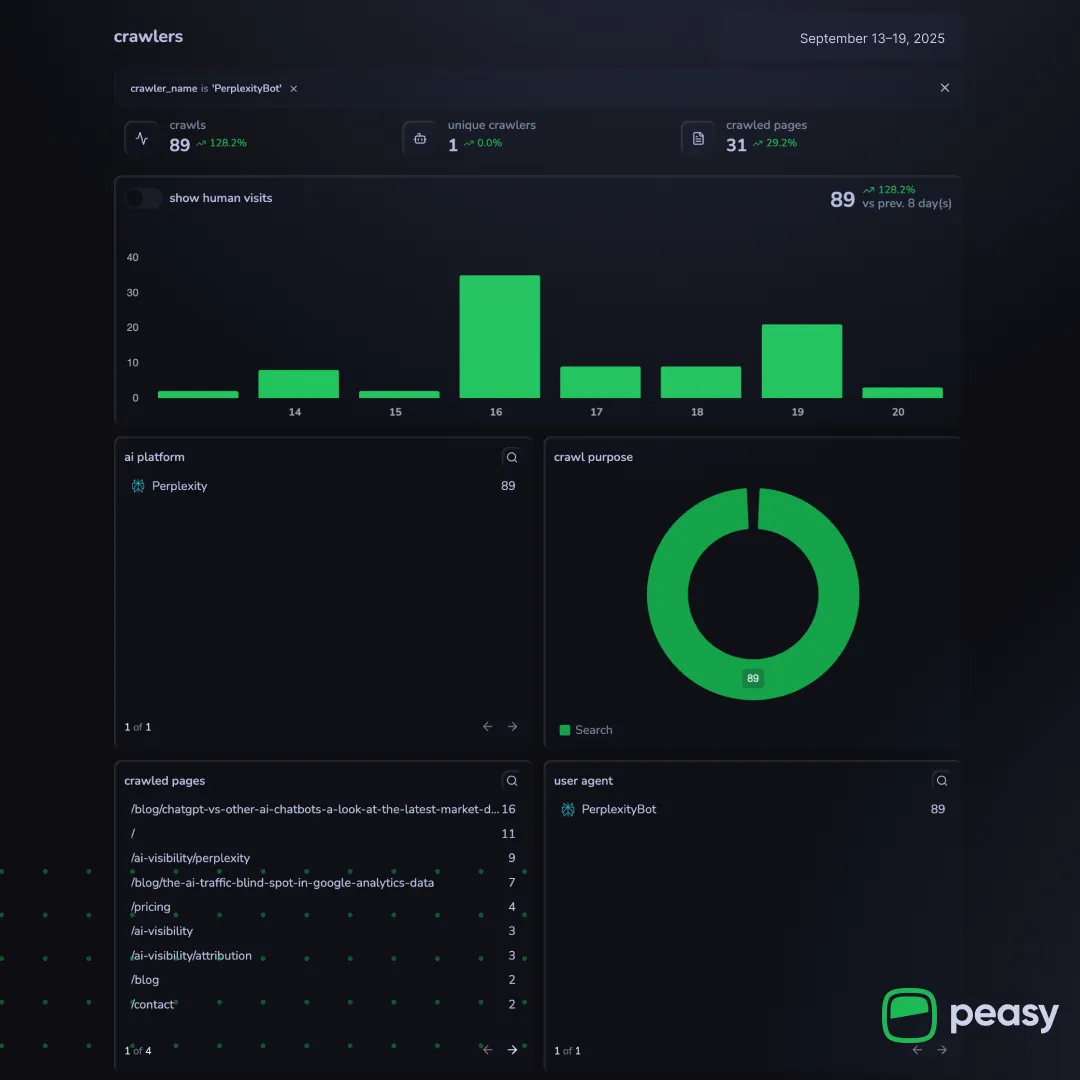 PerplexityBot made 89 search crawls, with activity focused on blog and visibility pages. |
|---|
-
Crawl intent skews heavily toward training/indexing, rather than chat retrieval. That means the majority of these visits are gathering data for model training or internal use, not necessarily driving traffic back to sites.
-
Click-throughs from AI answers remain rare. Our citation tracking shows that while AI platforms do generate inbound visits when users click a cited link, the ratio of crawls to clicks is heavily unbalanced.
This pattern matches external industry research. Cloudflare recently reported that roughly 80% of AI crawler traffic is training related, with referrals dwindling in comparison. In other words, your site is probably being read by AI crawlers far more often than it’s sending you measurable AI traffic.
Why Meta’s Activity Matters
Meta has been unusually transparent compared to some rivals. The company openly documents its Meta-ExternalAgent crawler, stating that it “crawls the web for use cases such as training AI models or improving products by indexing content directly”.
That’s significant for two reasons:
-
Public admissions: many AI companies avoid explicitly stating how their crawlers are used. Meta is clearer - it’s for training and product improvement. That leaves little ambiguity about intent.
-
Timing with licensing talks: Reuters reported this month that Meta is in discussions with publishers like Axel Springer, Fox and News Corp about licensing content for AI tools. If those deals are finalized, Meta will need to pay for access to some premium content. Until then, publicly available content is fair game under
robots.txtrules.
This raises a provocative possibility: is Meta ramping up its crawling now to gather as much content as possible before licensing limits apply?
Crawls vs. Visits
One of the biggest frustrations for publishers and marketers is that AI crawlers consume enormous amounts of content without proportionate traffic being sent back.
In traditional SEO, the social contract has been simple: publishers optimize for Google, Google shows links, users click and publishers get traffic. With AI crawlers, that loop is broken.
Cloudflare’s data shows the imbalance clearly: crawls are skyrocketing, referrals are flat or declining. Our Peasy data confirms the same - crawlers from OpenAI and Meta hit pages repeatedly, but only a fraction of those interactions ever result in inbound visits.
This creates an attribution blind spot: you may be contributing heavily to AI answers without realizing it, because your analytics tools simply don’t track crawler activity or AI referrals.
Implications for Publishers and Marketers
The implications go far beyond technical SEO.
-
Publishers and media companies are already negotiating licensing agreements with Meta and others. Understanding how much their content is being crawled gives them leverage. If crawlers are hitting thousands of pages a week, that’s evidence of real value being extracted.
-
Marketers and SEO teams need to recognize that AI assistants are now a visibility channel of their own. Optimizing only for Google keyword rankings misses a huge and growing slice of content discovery.
-
Privacy and content protection advocates have fresh concerns. If crawlers are indexing text fragments and using them in AI answers without attribution or referral, what does that mean for content ownership?
Peasy’s intent tracking sheds light on this by categorizing crawls as indexing, search or chat retrieval. That helps distinguish between background training activity and more active surfacing of content in user facing AI answers.
Meta’s AI Ambitions
This surge in crawler activity also aligns with Meta’s broader AI push. In the past year, Meta has:
-
Launched Meta AI, its consumer chatbot, across products like Instagram, Facebook and WhatsApp.
-
Formed a new superintelligence unit, aggressively hiring top AI researchers and engineers, often with large signing bonuses.
-
Signaled that AI integration is central to the future of its platforms, from search and recommendations to advertising and e-commerce.
All of this depends on high-quality, large scale training data. And that means crawlers like Meta-ExternalAgent are the quiet workhorses enabling Meta’s AI ambitions.
Why This Story Matters
Let’s be clear: none of this is illegal. If robots.txt permits, AI crawlers are allowed to index your site. But legality isn’t the only question.
-
For publishers, it’s about economics. If Meta is already consuming their content at scale, that matters in licensing talks.
-
For marketers, it’s about attribution. If traffic from ChatGPT or Perplexity is lumped into “Direct”, you’re losing visibility on how AI influences your funnel.
-
For the wider web, it’s about transparency. Users deserve to know how their content is fueling AI models, especially when attribution and referrals are inconsistent.
Our data shows that Meta is already a major crawler alongside OpenAI and that activity is heavily skewed toward training/indexing. Combined with ongoing licensing negotiations, that suggests a simple truth: AI companies are gathering content aggressively now, because the rules and costs are about to change.
Where Peasy Fits In
This is exactly why we built Peasy. Traditional analytics tools like GA4 ignore AI crawlers entirely - they don’t execute JavaScript, so they vanish from browser-based tracking. As a result, website owners are blind to how often AI companies are consuming their content.
Peasy closes that gap by:
-
Logging server-side crawler activity from OpenAI, Meta, Anthropic, Perplexity, Google and others.
-
Tracking AI referrals, including citations, quoted text fragments and scroll-to-text parameters.
-
Combining AI data with standard web analytics (visitors, funnels, conversions) in a unified dashboard.
-
Integrating with Google Search Console so keyword data sits alongside AI visibility metrics.
For the first time, you can see not only how humans find and use your content, but also how AI platforms crawl, cite and redistribute it.
What Comes Next?
We believe the next phase of digital marketing will require AI visibility analytics as much as SEO and traditional web analytics. Knowing how AI platforms crawl, cite and refer your content is now a critical part of understanding your audience reach.
At Peasy, we’ll continue to publish data snapshots and insights as this landscape evolves. In the meantime, website owners should ask themselves:
-
Which AI platforms are crawling my site today?
-
Is my content being used in AI answers and am I getting any measurable traffic back?
-
How does this affect my strategy for content, SEO and growth?
These are no longer theoretical questions. They’re live, measurable realities.
Attribute every AI visit to revenue and growth.
Easy setup, instant insights.
based on real user feedback