- AI
- Google Analytics
- AI Traffic
- Web Analytics
- AI Visibility
The AI Traffic Blind Spot in Google Analytics Data
Understand AI traffic in Google Analytics and how to solve measurement challenges shaping the future of web analytics

Team Peasy
The collective voice of Peasy, covering AI visibility, analytics and generative search optimization. LinkedIn
The way people discover information online is changing fundamentally. AI platforms like OpenAI’s ChatGPT, Perplexity AI and Google’s Gemini are creating a completely new category of web interaction. This new ecosystem operates on assumptions that are entirely different from those that modern web analytics platforms were built on.
This creates two separate forms of engagement. The first is direct user referrals, which happen when a person clicks a link or a citation in an AI answer. The second, much larger form of engagement is the “invisible” interaction: an AI platform’s crawler visits your website to collect, analyze and synthesize the information it needs to create that answer. This second category of interaction is almost completely unmeasured by standard client-side analytics tools like Google Analytics (GA4) and its alternatives. This creates a significant vacuum for any digital marketing or content strategy.
AI discovery is now a mainstream activity. A full 63% of websites already get traffic from AI tools. This traffic often shows higher engagement levels than visitors from traditional search engines. You have a strategic need to understand and optimize for this channel, yet the tools most businesses depend on are architecturally unable to show the complete picture.
Why AI Crawlers Don’t Trigger Google Analytics Tracking
The problem is a core architectural mismatch that cannot be reconciled. Google Analytics, along with the vast majority of its alternatives, is built on a data collection model that requires client-side Javascript to run in a user’s web browser. This event based model uses a Javascript code, also known as the Google Tag (gtag.js), to send data from the browser to analytics servers. It was designed for an era of real human browsing and was never intended to measure the activity of automated chatbots and AI crawlers that do not execute Javascript.
The gap in measurement is enormous. The ratio of AI crawler visits to the user referrals they eventually produce is very high. This indicates that the actual “interest” an AI has in your content is orders of magnitude greater than what your client-side analytics show.
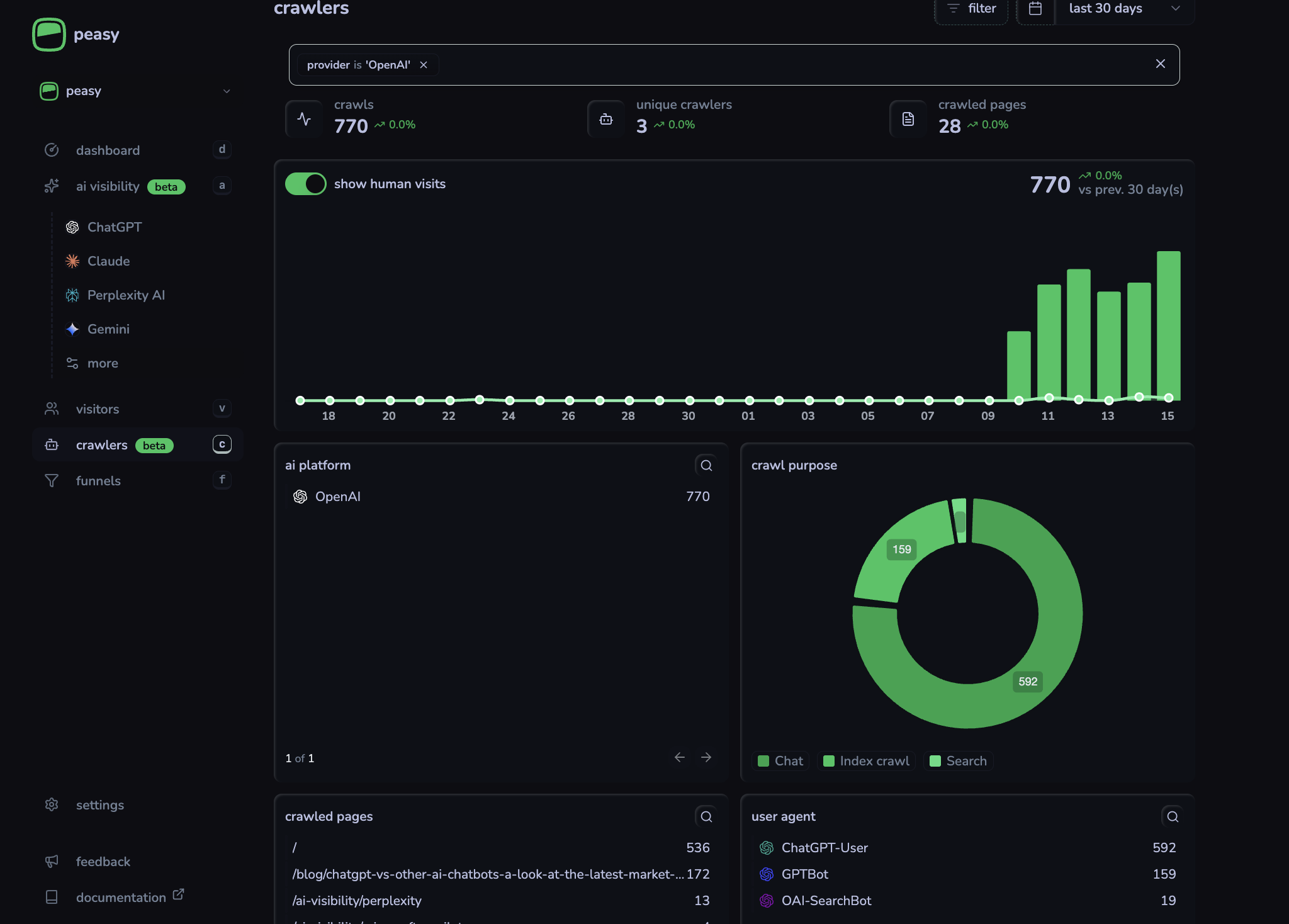
For example, even though Peasy’s website is relatively new, for for every single referral visit ChatGPT sends, it makes ~64 crawls, with the most active user agent being ChatGPT-User, reflecting pulls when users interact via prompts.
![]()
Sure, ratios will vary by site. But what does this disparity actually mean for your data? It means a platform like Google Analytics can, at best, only see the “1” in those ~64 interactions. The 63 preceding data points, which represent the AI’s direct engagement with your content, are completely lost. This leads to a profound misunderstanding of which content is truly valuable and influential in the AI ecosystem.
This failure to track AI crawler traffic is not a temporary bug or a feature that will be fixed in a future GA4 update. It is a permanent consequence of a foundational architectural divide. GA4’s design philosophy is to capture user interactions in a rendered, client-side browser environment. An AI crawler’s design philosophy is to efficiently scrape raw HTML for data ingestion. For a crawler, executing JavaScript is a computationally expensive step that is unnecessary for its primary goal. These two architectures are fundamentally incompatible. Any strategy that involves waiting for client-side platforms to solve this problem is flawed. To see this new traffic, you must adopt an analytics framework built on a different foundation.
How GA4 Collects Data (And How AI Crawlers Bypass It)
To understand the analytics blind spot, you must first understand how data collection works in Google Analytics. The entire GA4 data model depends on the successful execution of Javascript code inside a user’s browser. The process starts when a website loads the Google Tag (gtag.js), which is a Javascript library that acts as the main data collection agent.
Once this script runs, it collects a wide range of information from the browser’s environment. This includes parameters sent with every event, such as the page URL (page_location), the referring source (page_referrer), the page title (page_title) and the user’s screen resolution. This script is what triggers the foundational events in GA4, such as session_start, which begins a new session and page_view, which records that a page was viewed.
GA4 features like “enhanced measurement”, which automatically track user interactions like scroll depth, outbound clicks and form submissions, are also entirely dependent on this client-side Javascript. The script actively listens for these user actions and sends corresponding events to GA4’s servers. If the JavaScript does not execute, none of these events can be captured. From GA4’s perspective, the visit simply never happened.
AI crawlers operate in a completely different way. As we know by now, the definitive analysis shows that major AI crawlers, including OpenAI’s GPTBot, Anthropic’s ClaudeBot, Perplexity’s PerplexityBot etc. do not render Javascript. Their function is to send an HTTP request to a server and parse the initial, static HTML response that comes back. They do not have the browser-like rendering engine needed to execute the gtag.js script.
This behaviour is different from Google’s traditional web crawler Googlebot. Google has invested heavily in giving Googlebot sophisticated rendering capabilities, which allows it to process and index Javascript heavy websites. The reason for this difference comes down to purpose. Googlebot’s goal is to index the web for a search engine that serves results to humans, so it needs to see a page as a human would. In contrast, AI crawlers are data scrapers. Their goal is to collect massive amounts of text to train Large Language Models (LLMs) or to inform Retrieval Augmented Generation (RAG) systems in real-time. For this purpose, executing Javascript would create prohibitive computational overhead, drastically slowing down their data collection efforts.
Crawlers and How They Interact With Your Website
Analyzing the specific user agents of these AI crawlers provides concrete evidence of this technical divide.
-
GPTBotis OpenAI’s training crawler. It fetches public pages for model training and followsrobots.txt. It does not execute site Javascript. -
OAI-SearchBotpowers ChatGPT’s search features. It discovers and surfaces web results in ChatGPT and is controlled viarobots.txt. OpenAI addsutm_source=chatgpt.comto referrals so you can track clicks. -
ChatGPT-Useris used when ChatGPT fetches a page in response to a user’s prompt. OpenAI documents this user agent so that site operators can block it. Since these are user-triggered fetches, they are not pageviews in a browser running your GA tag. -
PerplexityBotindexes content for Perplexity’s search and respects robots.txt. -
Perplexity-Userfetches pages in real time for a user’s query and, by Perplexity’s own docs, generally ignores robots.txt because the request is on behalf of a user. Neither agent executes your site JavaScript. -
Google-Extendedis a robots.txt product token that controls whether Google can use your content for AI training. It is not a crawler. Crawling still happens throughGooglebotand related user agents. -
Googlebotrenders Javascript for indexing with a Chrome-based renderer, but its activity is not a human visit and is not what GA4 reports as a session.
| User agent or token | Operator | Purpose | Executes site JS | robots.txt behavior | Analytics implication |
|---|---|---|---|---|---|
| Googlebot | Crawling and indexing for Search | Yes, Google uses a Chrome-based renderer | Yes | Not a human visit, GA4 is client-side and does not treat Googlebot fetches as user sessions. | |
| GPTBot | OpenAI | Collect public pages for LLM training | No | Yes | Invisible to GA4 because no client-side tag runs. |
| OAI-SearchBot | OpenAI | Surface websites in ChatGPT search results, not for training | No | Yes, managed via robots.txt | Clicks from ChatGPT include utm_source=chatgpt.com, but the crawl itself is not a GA4 session. |
| ChatGPT-User | OpenAI | On-demand fetch for a user’s prompt in ChatGPT | No | Documented UA so sites can block it; not a training crawler | Server-side fetch, not a browser pageview, so GA4 does not record a session. |
| PerplexityBot | Perplexity | Indexing for Perplexity’s search results | No | Yes | Invisible to GA4. |
| Perplexity-User | Perplexity | On-demand fetch for a user query | No | Perplexity states it generally ignores robots.txt for user-requested fetches | Server-side fetch, not a GA4 session. |
| Google-Extended | Robots token to control AI training use | N/A | Respected as a token, actual crawling via Googlebot | Controls model training use, not crawling visibility. |
Debunking Flawed Fixes for Tracking AI Traffic
In an attempt to address the rise of AI traffic, some workarounds have become popular in the SEO community, especially on LinkedIn. These methods are fundamentally flawed and provide a dangerously incomplete picture.
The Regex Filter
One common method is to use regular expression (regex) filters in GA4. This involves creating filters in reports to isolate sessions where the referrer domain matches a list of known AI platforms, such as ^..openai.|.copilot.|.chatgpt.|.gemini.|.gpt.| .neeva.|.nimble.|.perplexity.|.*google.bard.|.*bard.google.|.bard.|.edgeservices.|.bnngpt.|.*gemini.google.$. The limitation of regex filtering is that it can only identify the final step in the AI interaction: a human user clicking a link in an AI response. It is completely blind to the thousands of preceding AI crawler interactions that gathered the information in the first place. This method only measures the tip of the iceberg.
This approach also has technical limitations. GA4’s regex engine has a 256-character limit, is case-sensitive by default and uses the RE2 syntax, which lacks some advanced features. These constraints make it difficult to maintain a comprehensive filter. Furthermore, the landscape of AI tools is expanding rapidly, so these regex filters must be updated perpetually to remain even partially effective. Regex filters create a false confidence that this new channel is being monitored, but they are based on a flawed premise. You end up observing only the tiny fraction of user clicks that carry a clean referrer string, while remaining blind to the 99.9%+ of AI interactions that are the true indicator of your content’s relevance.
The #:~:text= Scroll-to-Text Fragments
Another technique that SEO experts suggest is the scroll-to-text fragments. These are URL query strings, denoted by #:~:text=..., that tell a browser to scroll to and highlight a specific passage of text. They are commonly used by Google in featured snippets and when performing deep research using Chatgpt or Gemini.
Tracking these fragments in GA4 requires custom Javascript code. This code parses the URL, extracts the text fragment and fires a custom event to GA4. While this is useful for understanding how human users interact with content from traditional search engines, it is irrelevant to tracking AI crawlers. The entire mechanism depends on client-side Javascript execution. Since AI crawlers do not execute Javascript, they are oblivious to these URL fragments. This method works when analyzing the post-click behavior of humans, not the pre-response data gathering of automated agents. It offers no utility in solving the AI analytics blind spot.
The architectural limitations of client-side analytics do not just create a void of data but they actively corrupt your existing metrics.
”Direct” Traffic Is Becoming a Black Hole
In GA4, the “Direct” channel has become a catch-all for visits where no referral source is available. That bucket now includes traffic from privacy-based browsers, VPNs and, increasingly, AI chatbots.
By default, GA4 records a session as “Direct” when referrer data is missing. As more AI tools strip or mask this data, a growing share of AI visits is misclassified. The outcome is inflated “Direct” numbers that disguise the real role of AI platforms in driving users to your site. This makes brand recognition appear stronger than it is and hides which content is gaining traction inside AI ecosystems.
Many AI assistants, especially mobile apps and free chatbot versions, open links in environments that do not pass referral headers. GA4 cannot distinguish these visits from genuine typed in URL address visits, so they are assigned to “Direct” traffic.
There is, however, a way to correlate. If your logs show an AI crawler fetching a page shortly before a user session to the same page, that sequence can be used as a signal that the “Direct” visit originated from AI answer. Turning these invisible visits into attributable traffic creates a new measurement dimension, one that most analytics platforms cannot provide today.
How Misattributed AI Traffic Skews Marketing ROI
This widespread misattribution has severe ROI consequences. When a conversion that originated from an AI referral is incorrectly credited to the “Direct” channel, it distorts the picture of your marketing return on investment.
Consider this scenario: a user discovers your product through a detailed comparison generated by ChatGPT, clicks on the product URL in an app with no referrer and makes a purchase. In GA4, this high-value conversion is recorded as a “Direct” visit. When your marketing team analyzes channel performance, they will see that the “Direct” channel has a high conversion rate. Meanwhile, the content marketing performance - the very activity that created the high quality content the AI system used, will appear to be underperforming. This faulty data can lead to the logical but incorrect decision to shift budget away from content creation and toward brand building or PR activities perceived to drive “Direct” traffic. In reality, the company is systematically defunding the top-of-funnel engine that generates this valuable AI referral traffic, all because their primary analytics tool is providing misleading data.
The Solution: AI visibility Analytics for Ground Truth
The definitive solution for achieving complete traffic visibility is to shift the point of data collection from the client’s browser to the web server itself.
Server access logs provide an unfiltered, complete record of every single HTTP request that reaches your server, regardless of the client’s nature or capabilities. Each entry in a server log contains a rich set of data points that are essential for analyzing AI crawler activity.
By parsing and analyzing these raw server logs, it becomes possible to precisely quantify the full scope of AI platform interaction. This approach can definitively answer strategic questions that are impossible to address with client-side data. How frequently do AI platforms crawl the site? Which specific content are they consuming most often? Are there crawl errors preventing them from accessing valuable information etc.
Raw server logs are typically large, dense text files that require specialized tools for effective analysis. This is where a new category of AI visibility tools comes in. Tools like Peasy are built to solve the AI analytics blind spot by capturing and analyzing the full spectrum of web requests directly from the server.
The reliable tracking solution of Peasy is to unify traditional web analytics with AI visibility by directly tracking the activity of AI crawlers like GPTBot and PerplexityBot alongside human visitor activity. This server-side data collection method is the only reliable way to capture requests from non rendering agents.
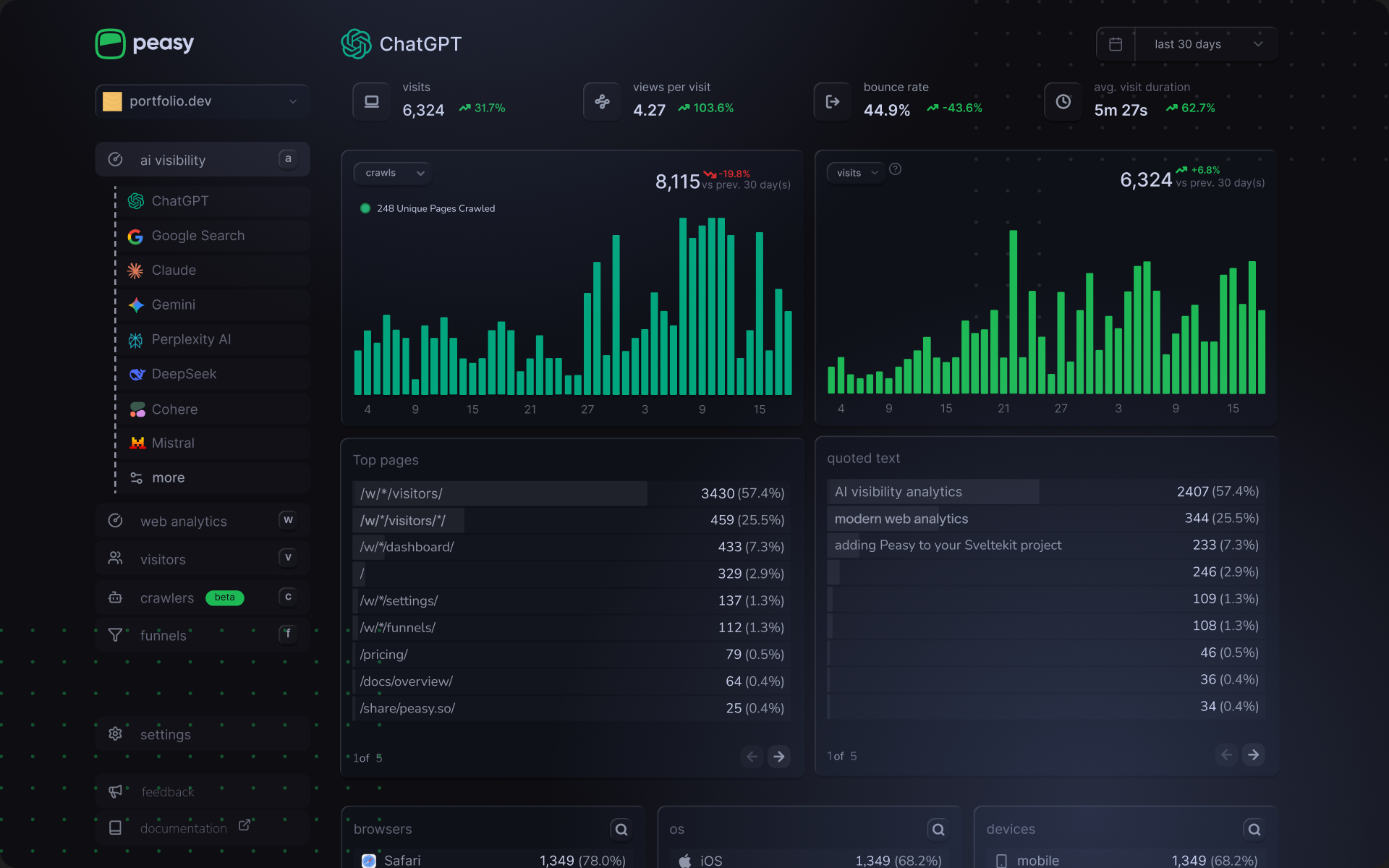
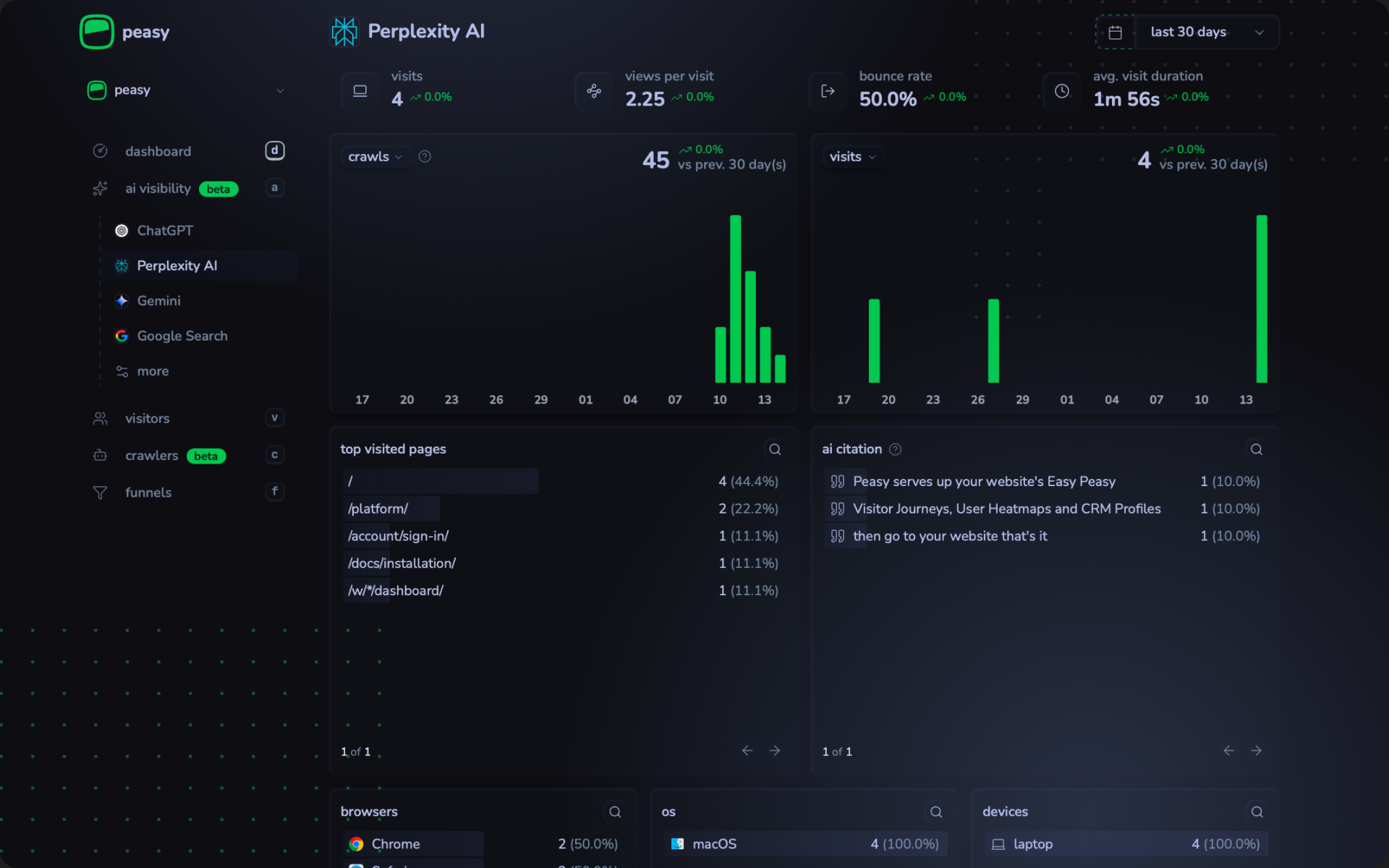
This provides a suite of features that are impossible to replicate with client-side-only tools.
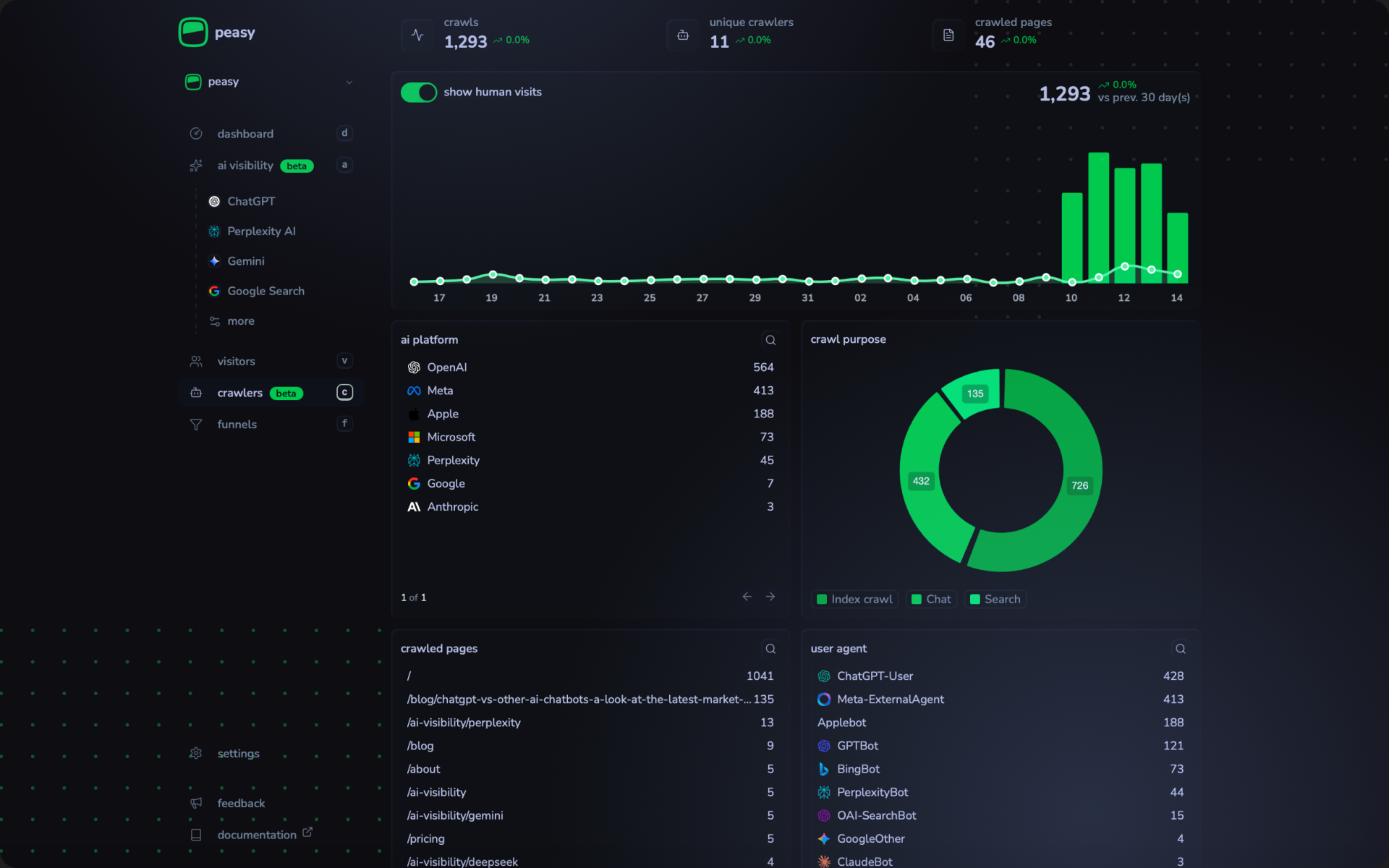
A New Strategy for a New Era of Web Traffic
To navigate this new landscape, your brand must adopt a more sophisticated approach to web analytics and content strategy.
The necessary response is not to abandon client-side analytics platforms like Google Analytics. These tools remain indispensable for understanding the behaviour of your human users - analyzing on-page engagement, conversion funnels and audience segments. They must now be augmented with a server-side analytics solution like Peasy. Server-side tools are essential for understanding your total traffic and content reach, including the full scope of AI platform interactions. The future of web analytics is a two-stack approach: client-side data for user experience and server-side data for the ground truth on content consumption.
Optimizing Content Strategy for AI Visibility
The insights from server-side analytics should directly inform your content strategy. Use these new data points to identify which pages and content pieces are most frequently accessed by AI crawlers. This content, which may be very different from the pages that perform well in traditional search, is your most “influential” content within the AI ecosystem. This influential content should be optimized for clarity, factual accuracy and structured data markup. The goal is to make it as easy as possible for AI systems to parse and synthesize your information, which improves the quality of AI-generated summaries and increases the probability of receiving high-intent user referrals.
Rethink Your Attribution Models
The established models of digital marketing attribution are breaking down. The “Direct” traffic channel in GA4 and its alternatives can no longer be considered a clean metric for brand strength. It is now a polluted repository for untraceable AI referrals. Use server-side data to look for correlations between spikes in AI crawler activity on specific content and subsequent, otherwise unexplained increases in “Direct” traffic to those same pages. This correlational analysis helps reveal the true impact of AI as a discovery channel.
The behaviour of agents like Perplexity-User, which ignores robots.txt directives, signals a future where traditional methods of controlling bot access become less effective. In this environment, the most effective optimization strategy is providing high-value, well structured and easily parsable content. The era of assuming that all important traffic executes Javascript is over. The era of AI visibility analytics has begun.
Attribute every AI visit to revenue and growth.
Easy setup, instant insights.
based on real user feedback